ID:PATL1_HUMAN DESCRIPTION: RecName: Full=Protein PAT1 homolog 1; AltName: Full=PAT1-like protein 1; AltName: Full=Protein PAT1 homolog b; Short=Pat1b; Short=hPat1b; FUNCTION: RNA-binding protein involved in deadenylation-dependent decapping of mRNAs, leading to the degradation of mRNAs. Acts as a scaffold protein that connects deadenylation and decapping machinery. Required for cytoplasmic mRNA processing body (P-body) assembly. In case of infection, required for translation and replication of hepatitis C virus (HCV). SUBUNIT: Interacts (via region A) with DDX6/RCK. Interacts (via region H and region C) with LSM1 and LSM4. Interacts (via region N) with DCP1A, DCP2, EDC3, EDC4 and XRN1. Interacts with the CCR4- NOT complex. Interacts with the Lsm-containing SMN-Sm protein complex. SUBCELLULAR LOCATION: Cytoplasm, P-body. Nucleus. Nucleus, PML body. Nucleus speckle. Note=Predominantly cytoplasmic. Shuttles between the nucleus and the cytoplasm in a CRM1-dependent manner. Enriched in splicing speckles. Localization to nuclear foci and speckles requires active transcription. Excluded from the nucleolus. TISSUE SPECIFICITY: Ubiquitous. DOMAIN: The region A, also named N-term, mediates the interaction with DDX6/RCK and is required for cytoplasmic mRNA processing body assembly. DOMAIN: The region C, also named Pat-C, is required for RNA- binding and mediates the binding with the Lsm-containing SMN-Sm protein complex and the decapping machinery. It folds into an alpha-alpha superhelix, exposing conserved and basic residues on one side of the domain. SIMILARITY: Belongs to the PAT1 family. SEQUENCE CAUTION: Sequence=CAD89916.1; Type=Erroneous initiation; Note=Translation N-terminally shortened;
The RNAfold program from the Vienna RNA Package is used to perform the secondary structure predictions and folding calculations. The estimated folding energy is in kcal/mol. The more negative the energy, the more secondary structure the RNA is likely to have.
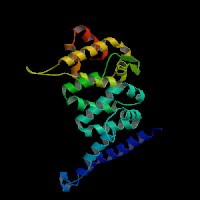
ModBase Predicted Comparative 3D Structure on Q86TB9
Front
Top
Side
The pictures above may be empty if there is no ModBase structure for the protein. The ModBase structure frequently covers just a fragment of the protein. You may be asked to log onto ModBase the first time you click on the pictures. It is simplest after logging in to just click on the picture again to get to the specific info on that model.
Orthologous Genes in Other Species
Orthologies between human, mouse, and rat are computed by taking the best BLASTP hit, and filtering out non-syntenic hits. For more distant species reciprocal-best BLASTP hits are used. Note that the absence of an ortholog in the table below may reflect incomplete annotations in the other species rather than a true absence of the orthologous gene.
 Sequence and Links to Tools and Databases
Sequence and Links to Tools and Databases